[Deep Learning] Activation Function
in DeepLearning on Tech, Tensorflow
활성화 함수의 역할
딥러닝의 인공신경망에서 활성화 함수는 매우 종요하다 하지만 이에 대한 역할과 중요성을 제대로 공부하지 못하였는데 이번기회에 공부하도록 하자 활성화함수는 인공 신경망에서 입력받은 데이터를 다음층으로 출력할지를 결정한다 모델에서 뉴런은 층으로 구성되고 층에는 여러개의 노드로 구성되어있다. 하나의 노드는 1개 이상의 노드와 연결되어 있고 데이터 입역을 받게 되는데 연결강도의 가중치의 합을 구하게 되고 활성화 함수를 통해 가중치의 값이 가중치의 값의 크기에 따라 출력하게 된다 즉 현재 뉴런의 input을 feeding하여 생성된 output이 다음 레이어로 전해지는 과정 중 역할을 수행하는 수학적인 게이트(gate)라고 할 수 있다.
또한, 활성화 함수는 각 뉴런의 output을 0과 1 또는 -1과 1 사이로 normalization 하여 모델이 복잡한 데이터를 학습하는 데 도움을 줍니다.
이진 활성화 함수, 선형 활성화 함수, 비선형 활성화 함수의 세 가지 종류가 있습니다. 결론적으로 말하자면, 이진 활성화 함수, 선형 활성화 함수 모두 큰 문제점이 존재하기에 비선형 활성화 함수만 사용되는 추세입니다.
비선형함수를 알아보자
1. Sigmoid함수
로지스틱 함수라고도 하며 x값의 변화에 따라 0에서 1까지의 값을 출력하는 S자형 함수이다.

장점으로는 유연한 미분값을 가진다 입력에 따라 값이 급격하게 변하지 않는다 또한 출력값의 범위가 0과 1사이로 제하됨으로써 정규화 중 exploding gradient 문제를 방지한다 마지막으로 미분식이 단순한 형태를 지녀 깔끔한 예측값을 가진다
하지만 입력값이 아무리 커도 미분값의 범위가 0과 1/4 사이로 제한됨으로써 층이 많을 수록 gradient값이 0에 수렴한다.즉 입력값에 상관없이 활성화 함수로 인하여 기울기변화량이 거의 없다시피 해지는 vanishing gradient문제가 발생한다는 것이다 또한 출력의 중심이 0이 아니므로 뉴런으로 들어오는 데이터가 항상 양수인 경우 gradient는 모두 양수 또는 음수가 된다 이는 gradient업데이트 중 지그재그로 변동하는 문제점이 발생한다
Tanh
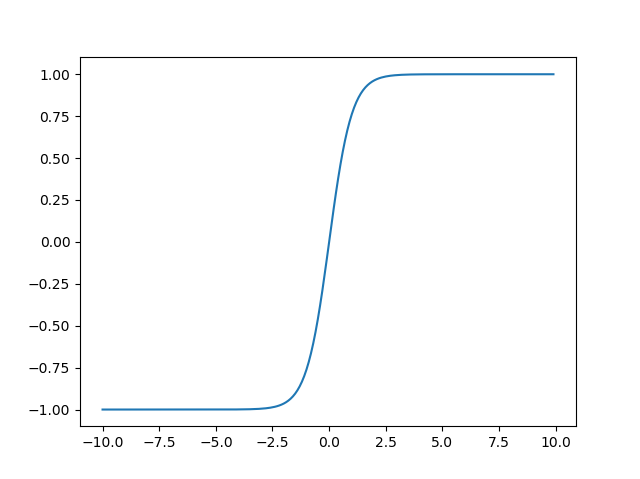
특징은 시그모이드와 유사하지만 출력의 중심이 0에 있다는 장점이 있다 시그모이드가 가지는 문제점을 일부 보완한다.
ReLU활성화 함수
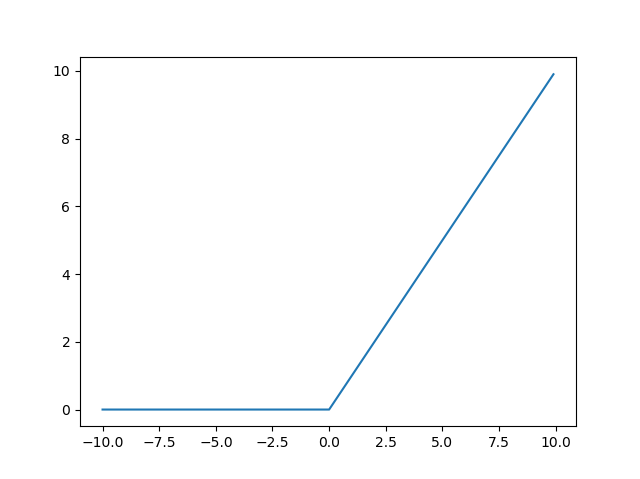
가장 많이 사용되는 활성화 함수 중 하나이다 값이 0보다 작거나 같으면 0 , 0보다 크면 선형함수에 값을 대입한다. 일부 정보는 과감히 무시하고 일부 정보는 수용하는 것을 통해 다른 활성화 함수에 비해 효율적인 결과를 보인다
장점으로는 비교연산 1회를 통해 값을 구할 수 있어 빠른 연산을 보여 다른 활성화함수에 비해 수렴속도가 매우 빠르다.(약 6배)
하지만 값이 음수인 경우 학습을 할 수 없다
LeakyReLU

Leakyrelu는 LeakyReLU_a(x) = max(ax ,x)의 식으로 이루어진다 하이퍼파라미터인 a가 leakyrelu에서의 새는 정도(기울기)를 결정하며 일반적으로 a= 0.01정도로 설정된다 즉 0이하인 입력에 대해 활성화 함수가 0만을 출력하기 보다는 입력값에 a만큼 곱해진 값을 출력으로 내보내어 deadReLU문제를 해결한다
ELU(Exponential Linear Unit)

ELU는 X<0 일때 ELU 활성화 함수 출력의 평균이 0(zero mean)에 가까워지기 때문에 편향 이동(bias shift)이 감소하여 그래디언트 소실 문제를 줄여준다. 하이퍼파라미터인 a는 x가 음수일 때 ELU가 수렴할 값을 정의하며 보통 1로 설정한다. x< 0 이여도 gradient가 0이 아니므로 죽은 daed뉴런을 만들지 않는다