[CS231N] lecture5 review
in Summary on Summary, Cs231n
what is CNN
CNN이란
맨 처음 시작은 MARK1 perceptron이라는 것이다. 단순히 기게로 동작했고 일반적인 단층 퍼셉트론방식이다 이는 w값을 조절해 가며 train시켰디. 이후 1986년도 오차역전파를 개념이 등장하였으나 인기를 끌지 못했고 점차 발전해 나갔다. 그러다 2012년 딥러닝이 소개되어 분위기를 활기 시켰다 바로 AlexNet구조 때문인데 이 모델은 imagenet에서 사람보다 더 뛰어나게 인식 할 수 있도록 설계되었고 그 성능또한 뛰어났다.
이때 사용한 방밥이 CNN이고 관련 모델을 통해 발전이 이루어진다. 이 alexnet도 큰것 -> 섬세한 것으로 특징을 추출해냈고 그 결과 엄청한난 정확도를 부여주었다,
컴퓨터 비전영역에서 사용되는 detection segmentailemdeh 등도 CNN으로 함께 할 수 있다.
fully connect layer

우리는 과거에 단순히 input image를 쫙 늘리다(flatten)해서 wx에 넣고 탐지를 하였다, 이는 역시나 좋지 못한 방법인데 앞서 선형적인 가설함수가 한계점을 지니는 예제등을 보았다. 따라서 이러한 방법을 바꾼다.

32x32x3이미지에 5x5x3 convolve filter를 걸치게 되어 하나의 activation map이 나오게된다 즉 필터를 통해하나의 특징맵을 만든다는 애기이다.

필터는 하나가 될 수도 있고 여러개의 필터를 사용할 수 도 있다. 만약 다른 필터를 사용하게 되면 이렇게 초록색의 필터가 하나 더 나오게 될것이다.

실제로 이렇게 시각화를 해보면 이렇게 나온다 첫번째 게층을 보면 색상, edgy등 각 영역의 다양한 모양을 가지고 있다. 그리고 아래층을 가면 갈 수록 더 자세한 영역까지 다루어진다는 것을 알 ㅅ수 있다.

실제 자동차 앞부분을 보면 위 처럼 나오게된다 아까 하나의 필터는 하나의 activation map을 만든다고 했는데 위의 작은 사진들이 filter들이다 그리고 아래 activation map이 있는데 이를 시각화 한것이다 예를들어 파란색 화살표의 경우 filter는 빨간색부분을 강조하는데 activation map에서 빨간색부분만 강조된 사진을 볼 수 있다

CNN은 대체적으로 위와 같은 깊은 신경망을 이루는데 지금 알아본 COnv를 지나 ReLU 활성화 함수를 거쳐 pooling을 만나고 진행된다. 추가적으로 나타나는 사진은 회색 아니면 검정색으로 나타나게 되는데 이는 ReLU를 거침으로써 0이하의 값들은 전부 0으로 만들기 떄문이다.
반대로 ReLU를 하기 전에는 음수의 값을 하지 않으므로 회색까지 포함되어 있다.
CNN 동작방식

간단하게 보아서 7x7의 input과 3x3filter가 있다 가정했을때 depth가 3이라면 아래와 같이 움직인다.

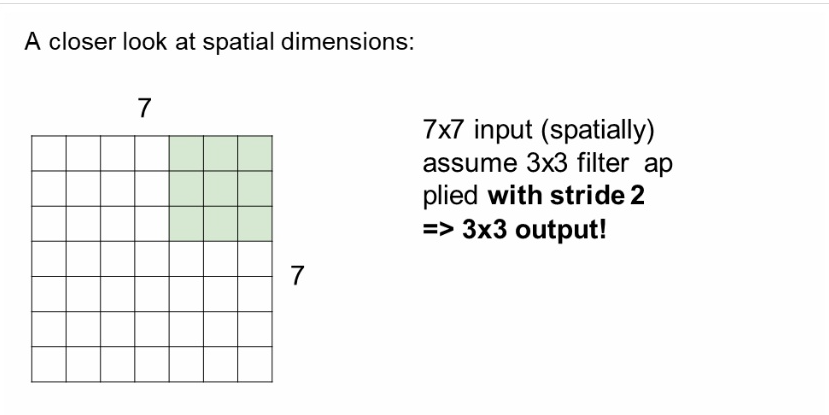
이렇게 3x3 filter가 움직일 수 있는 거리는 5번이다 세로도 마찬가지이므로 output은 5x5가 나온 것이다. 이떄 stride 즉 움직이는 거리는 1로 설정하였는데 이는 3이 될 수 동 있고 5가 될 수 도 있다 하지만 input에 맞는 크기를 설정해주어야 하며 관련된 공식은 아래와 같다.

N은 inputsize이며 F는 filter의 사이즈이다 이게 딱 떨어지지 않는다면 나오지 않는 것이다
padding

여기서 패딩개념을 추가하는데 이렇게 stride를 주어 conv과정을 거칠경우 어쩔 수 없이 input이 작아지게 된다 이게 이미지가 급격하게 작아지게 되면 cnn층을 몇개 쌓지도 않았는데 금세 image가 없어지게 된다 또한 중간에 있는 영역들은 filter들이 중복해서 겹쳐서 보게된다
가장 큰 문제는 imagesize가 작아진다는 것인데 zeropadding은 위 그림과 같이 양쪽사이드에 zero값을 둘러준다 즉 padding을 1개 추가하게 되면 7x7이미지는 9x9의 이미지가 된다

1x1 CONV
따라서 일반적으로 filter가 3이면 zero padding을 1개만 하고 filter가 5이면 zero padding을 2개를 한다는 것이다.

1x1 conv의 내용이다 이것으 앞에서 본 5x5이 런식이 아닌 1x1이 사용된다 이게 나중에 CNN을 거치고 나서 Flatten()을한다. 이는 공간적인 정보를 담고 있지 않지만 depth만큼 연산을 한다.

위 그림은 같은 위치에도 불구하고 필터가 다르기때문에 다른 값이 나온다는 것이다 즉 추출되는 특징이 다르다는 것이다,.
pooling
pooling은 이미지의 사이즈를 줄여준다 여기서 maxpooling은 큰 특징값을 유지하면서 줄여준다는 것이 포인트이다.

일반적으로 pooling filter가 2면 filter size가 2나 3일때 stride는 2를 사용한다.
FCN

이렇게 이미지로부터 추출한 특징을 이용해 FC로 분류를 한다.