[CS231N] lecture6 review
in Summary on Summary, Cs231n
Training Nerual Networks Part1
이번에는 Neural Networks를 학습시키는 것에 대해 나누어 수업을 진행한다 이에 관한 코드 실습(assignment)는 AI_KMU에 저장되어있다.

Activation Function은 Wx에대해 input이 들어오면 다음 노드로 보낼 때 어떻게 보낼지 결정해주는 역할을 한다.
따라서 활성화함수의 역할은 모델에서 매우 중요한 역할을 하는데 모든 활성화 함수는 비선형한수인 이유를 알기 위해 이를 정리하였다.

위 그림과 같이 활성화 함수가 선형함수 일시 레이어를 아무리 깊게 쌓아도 그 이점을 살릴수 없기 때문에 활성화 함수는 비선형 함수를 사용한다. 아래에서부터 활성화함수의 종류를 살펴보고 이에대한 단점과 이점을 살펴본다.

1. sigmoid

sigmoid함수는 3가지 문제로 인해 활성화 함수로 사용되지 않는다
problem #1 : gradient vanshing(기울기소실)
sigmoid함수 그래프 모양을 보면 x=10인 부분에서 기울기가 0에 가까운 것을 알 수 있다 또한 기울기의 최대값이 0.5로서 backpropagation을 하게 되면 모두 최대 값이라고 해도 게속해서 gradient가 작아지기 때문에 layer를 많이 쌓은 경우 기울기가 소실된다.
Problem #2 : not zero centered


시그모이드 그래프를 보면 0을 중심으로 되어 있지 않다는 것을 확인할 수 있다. 즉, 모든 input에 대해 양수 값으로 output이 나오게 된다. sigmoid로만 쌓으 ㄴ레이어를 확인해보면 시그모이드의 기울기 output값 모두 양수이기 때문에 DL/Da에 의해(input) 부호가 결정되고 모두 양수일 경우나 음수일 경우 대각선으로 가지 못하고 학습속도가 느려지게된다.
Problem #3 : compute expensive of exp()
exp의 연산의 값이 어렵고 비싸기 떄문에 좋지않지만 이는 그렇게 신경 쓸 문제는 아니다.
2. Tanh
 sigmoid의 단점을 개선하기 위해 zero centered된 tanh를 사용했지만, gradient vanishing과 exp 연산의 문제가 있어 잘 사용하지 않는다.
sigmoid의 단점을 개선하기 위해 zero centered된 tanh를 사용했지만, gradient vanishing과 exp 연산의 문제가 있어 잘 사용하지 않는다.
3. ReLU

가장 대중적으로 사용하는 activation function인 Relu이다. 0이하의 값을 가진 input은 0으로 내보내 주고, 그 이외의 것들은 그대로 내보내준다. ReLU에도 2가지문제가 존재하는데 nonzero-centured와 0이하의 값들은 모두 버려지게 된다는 것이다.

만약 데이터의 집합을 점수화했을때 값이 음수일 경우 이러한 상황을 dead relu이다 이를 해결하기 위해 bias값을 넣어주기도 한다.
4.Leaky ReLU

ReLU에 대한 보완으로 Leaky ReLU가 나오게 되는데 0이하의 값에 대해 작은 양수의 값을 주는 것이다. 그리고 이 것을 조금 변형한게 PReLU인데, 일종의 알파 값을 주고 학습을 통해 찾아가는 방법이다.
5.ELU
 또한 ReLU의 변형으로 나온 ELU도 있다. ReLU의 모든 장점을 가지고 있고, zero mean과 가까운 결과가 나오지만, exp() 연산이 있다는 단점이 있다.
또한 ReLU의 변형으로 나온 ELU도 있다. ReLU의 모든 장점을 가지고 있고, zero mean과 가까운 결과가 나오지만, exp() 연산이 있다는 단점이 있다.
Data Processing

데이터 전처리는 zero-centured , normalized를 많이 사용한다 zero-centured는 앞서 본 것처럼 양수, 음수를 모두 가지는 행렬을 가질 수 있게 해서 효율적으로 이동할 수 있다는 장점이 있고(학습이 빠름) normalized는 표준편차로 나눠주어 데이터의 범위를 줄여 학습을 더 빨리 할수 있다
Weight Initialization
weight가 어떻게 초기화 되어있는지에 따라 학습의 결과에 영향을 줌으로 중요한 영역이다 즉 출발점을 결정한다.

만약 W=0인 경우 output layer가 모두 0이 나오게 되고 gradient도 0이 나와 정상적으로 학습이 가능하지 않다.
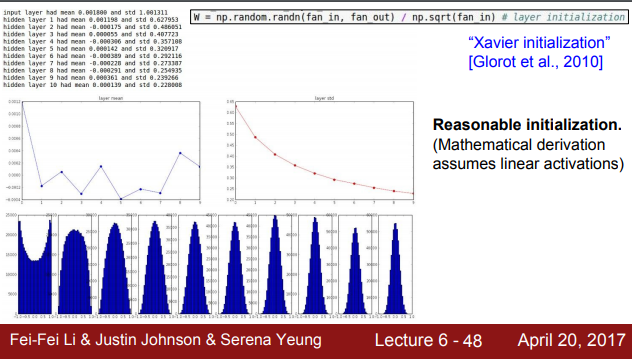 적절한 weight초기값을 주기 위해 XAvier init을 사용하게 된다. 노드의 개수르 ㄹnormalization하는 방법으로서 input의 개수가 많아지만 크게 나눠주기 때문에 값이 작아지고, input의 개수가 적으면 weught갑싱 커지는 방식으로 weight를 초기화하게 된다.
적절한 weight초기값을 주기 위해 XAvier init을 사용하게 된다. 노드의 개수르 ㄹnormalization하는 방법으로서 input의 개수가 많아지만 크게 나눠주기 때문에 값이 작아지고, input의 개수가 적으면 weught갑싱 커지는 방식으로 weight를 초기화하게 된다.
gradient vanashing 현상을 완화하기 위해 가중치를 초기화 할 때 출력값들이 정규 분포 형태를 갖게 하는 것이 중요하다 정규 분포형태를 가져야 안정적인 학습이 가능하기 때문이다.
BatchNormalization

Batch Normalization은 각 층의 input distribution을 평균 0, 표준편차 1로 만드는 것이다. network 각 층의 activation 마다 input distribution이 달라지는 internal covariance shift이 달라지는 문제를 해결하기 위해 사용 된다.

보통 batch별로 데이터를 train시키는데 이때 N*D의 batch input이 들어오면 이것을 normalize한다

BN은 일반적으로 활성화층 전에 사용되어 잘 분포되도록 한 후 activation을 진행 할 수 있도록 한다 BN이 목적이 네트워크 연산 결과가 원하는 방향의 분포대로 나오는 것이기 때문에 확성화함수가 적용되 분포가 달라지기 전에 적용하는 것이다.

하지만 BN이 적절한지에 대한 판단을 학습에 의하여 조절할 수 있다고 한다. 처음 normalize를 진행하고, 이 후 감마 값과 같은 하이퍼 파라미터 값들을 조정하여 batch norm을 할지 안할지 선택하는 것이다. 감마 값은 normalizing scale를 조절해주고, 베타 값은 shift를 조절해주는 파라미터 값이다. 이 값들을 학습을 통해 조절함으로서 normalize 정도를 조절할 수 있다.

먼저 평균과 분산을 구하고 normalize를 한다 그리고 scale shift를 얼마나 할지 학습을 통해 값을 정하게 된다.
그리고 BN를 하게 되면 Dropout를 사용하지 않아도 된다고 한다. 이 부분이 궁금해서 더 찾아봤는데, Batch Norm의 논문 저자는 dropout을 대체할 수 있다고 하였으나, 실제적으로 둘 다 모두 사용했을 때 성능이 좋은 경우도 있고 의견이 다양하게 존재하는 것 같다.
parameter
 이렇게 hyperparameter를 찾기 위한 방법으로 Grid Search와 Random Search가 있는데, Grid Search는 일정한 간격을 가지고 있어, 제일 best case를 찾지 못할 수도 있다. 그래서 Random Search 방법을 더 많이 사용한다고 한다.
이렇게 hyperparameter를 찾기 위한 방법으로 Grid Search와 Random Search가 있는데, Grid Search는 일정한 간격을 가지고 있어, 제일 best case를 찾지 못할 수도 있다. 그래서 Random Search 방법을 더 많이 사용한다고 한다.