[CS231N] lecture11 review
in Summary on Summary, Cs231n
attention
최근 연구 방향

2021년 기준으로 최신 고성능 모델들은 Transformer 아키텍처를 기반으로 하고 있다. 이전에 배운 RNN방식을 사용하는 것보다 Attention기법을 사용하는 것이 성능이 더욱 좋았기에 최근의 모델들은 attention만을 사용하는 모델들을 보이고 있다 즉 이는 입력 시퀸스 전체에서 정보를 추출하는 방향이라고 할 수 있다.
기존 seq2seq모델들의 한계점

위의 그림과 같이 입력 벡터를 고정된 크기의 context vector로 만든 후 이를 이용해 번역을 하게 된다 즉 하나의 sequence에서 다른 sequnce로 변환한다. 대충 원리는 이렇다 각 단어마다 나오는 h를 통해 문장 전체를 대표하는 벡터인 h4를 만들고 이를 통해 고정된 크기의 vector를 만든다 여기까지를 encode 단게라 하고 이후 decode단계에서는 아까 생성한 context 벡터에서 입력된 단어화 함계 또 다른 히든 스테이트값 s를 생성한다 이러한 반복을 end token이 나올때 따기 진행한다.

하지만 고정된크기의 정보압축은 다양한 경우의 수에서 병목현상이 발생할 수 도 있는 것이다. 이를 context vector를 decoe과정에 전부 직접 넣어줌으로써 해결한다 하지만 context vector를 생성해야하기 때문에 병목현상이 발생 할 수 있다.

이러한 병목현상을 해결하기 위해 매번 소스 문장에서의 출력 전부를 입력으로 받는다(아까의 h값들)러한 연산은 최신 cpu와 빠른 병렬처리를 통해 가능해졌다.

그 구조는 위와 같다. 입력 시퀸스에서 만들어진 h값들을 저장해놓고 이를 decode과정에 넣어준다. 이때 w는 가중치 합이다 입력 벡터를 통해 만들어진 h는 본 문장에서 해당 단어의 중요성을 수치화 한것이고 이를 sofmax를 통해 수치화 한후 더한 값이라고 할 수 있다. 물론 이전의 context vector또한 입력값으로 들어가게된다 이러한 과정은 촐력값이 생성될 때 마다 수행되며 rnn이 들어가 있으므로 이전의 출력값또한 입력값으로 들어가게 된다. 출력값은 good과 같은 형태이다.

가중치에대해 좀더 이야기 해보면 w는 가중치합이라 했는데 이때 가중치는 에너지의 softmax값이다. 에너지는 이전 히든스테이트 값과 인코더에서의 히든 스테이트 값들을 묶어서 만들어진다 이후 각 단계에서 해당단어에 얼마나 집중할지를 수치화한 가중치를 만들고 이를 행렬곱을 통해 디코더에서 사용한다(즉 모든 h를 사용)
attention의 시각화

가중치를 사용해 각 출력이 어떤 입력 정보를 참고 했는지 알 수 있다.
transformer

문장내 순서의 정보를 주기 위해 Positional encodeing을 사용한다 이러한 레이어는 반복해서 수행된다 왼쪽값으 인코더가 되고 오른쪽은 디코더가 된다.
Transformer의 동작원리 : 입력값 임베딩

어떤 문장이든 임베딩을 통해 네트워크에 넣어주게 되는데 이때 행은 embed_dim으로 모델의 구조를 설게 할때 임의로 생성한다 논문의 작성자는 512개의 차원을 두었다.

이후 RNN을 사용하지 않기위해 각 문장의 단어 위치정보를 주기위해 positional encoding정보를 넣어주고

Transformer의 동작원리 : 인코더와 디코더
attention에 넣어준다. 이때 attention에는 각 단어들의 연관성과 위치정보를 학습하기 때문에 문맥을 학습한다고 할 수 있다.

추가적으로 잔여학습을 추가했는데 이는 학습과정을 쉽게 만드는데 의의가 있다.

atteion layer와 feedforward layer의 블럭을 N번 반복한다 이때 각 블럭은 가중치가 다르다

이렇게 나온 값을 디코더에 모든 attention layer에 줌으로써 성능을 올린 것이다. 이때 나온 값은 문장의 위치에 따른 문맥정보라고 할 수 있을 것 같다. 이렇게 추가된 값은 attention에서의 출력값이 소스 문장에서 어떤 단어와 연관성이 있는지를 알 수 있다.

레이어는 인코와 디코더와의 수와 같게 만든다.

rnn와 lstm에서 각각의 단어에 따라 히든 스테이트가 생성되었다고 하면 transformer에서는 한번에 모든 입력값들을 넣어서 병렬적으로 출력값을 생성한다. 따라서 계산복잡도가 낮아지게 된다. 하지만 디코더에서는 eos가 나올때 까지 반복하여 출력값을 생성한다.
Transformer의 동작원리 : attention

attention기법은 어떠한 단어가 다른 단어들과 어떠한 연관성을 가지는 지를 알아 내는 것이다 즉 쿼리는 무언가를 물어보는 주체이다 물어보는 대상이 key라고 할 수 있다. 위의 구조를 보면 쿼리와 키가 합성곱을 통해 연관성을 가지게 하고 이를 softmax를 통해 수치를 정량화한다. 그렇게 오른 쪽을 보면 각 문장에 대한 v와 k와 q에 대해 각각의 scaled dot-product attention연산을 통해 h개의 서로 다른 attention concept을 만들어 더욱더 구분된 연관성을 학습 할 수 있다는 장점 있다고 한다. attention값들을 concat을 통해 붙힌다음 linear를 통해 ouput을 dimention을 줄어들지 않게 한다.

 d_model은 love의 임베딩차원(임의로 설정)이고 h는 헤드의 개수이다
d_model은 love의 임베딩차원(임의로 설정)이고 h는 헤드의 개수이다

다시한번 순서를 되짚어 보자면 쿼리 해당하는 벡터를 각 문장의 단어 키 벡터에 합성곱을 통해 그 연관성을 계산하고 이를 softmax가 잘 학습할 수 있도록 d로 스케일링 해준다. softmax를 취해 실제로 각각의 key value에대해 연관성을 정량화한다. 각각의 가중치값을 value값을 곱해준다음 더해주면 마지막인 atteintion 값을 구할 수 있는 것이다.

추가적으로 만들어진 에너지 매트릭스에서 원소곱을 통해 mask를 해줄수 있다. 즉 관여하게 하고 싶지 않은 단어를 제거 할 수 있다.

아까 head의 값만큼 쿼리와 키와 밸류를 생성 했으므로 나오는 attention value또한 h개가 나온다
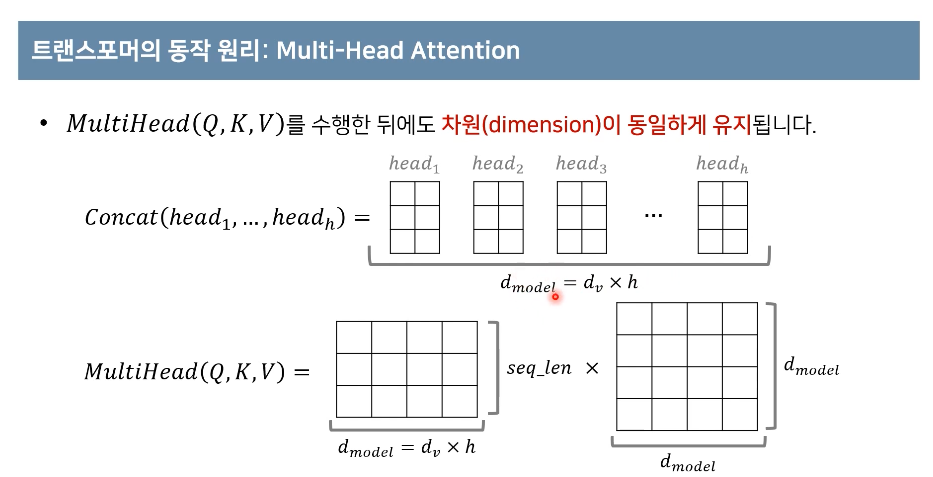
이렇게 만들어진 멀티헤드 attention value matrix를 concat하여 차원이 동일하게 유지될 수 있게 해준다 그리고 만들어진 d x d 차원의 매트릭스와 input sequnce를 곱하여 멀티헤드 값을 얻을 수 있다.


이는 self- attention을 통해 입력문장에서 각단어가 다른 단어와 어떤 연관성을 가지는지 알 수 있다.
2021-10-5일 추가수정
단어임베딩
Transformer자체에는 입력 시퀀스 위치에 대한 정보가 없으니 positional encoding이 필요하다. 이를 정의해보자면 주어진 시퀀스에서 특정한 위치를 유한한 차원의 벡터로 나타낸 것을 말한다. 예를 들어 시퀀스 A[a1, a2 ,a3]가 주어졌을때 Positianal encoding의 결과는 시퀀스의 원소의 위치와 원소의 위치에 대한 정보를 담고있는 텐서가 될 것이고 Transformer에서는 입력 시퀀스의 각원소별 임베딩 결과와 positional encoding의 결과가 더한 값을 단어임베딩의 입력으로 하기 때문에 positional encoding의결과는 [시퀀스의 길이 , 임베딩 차원]의 크기를 가져야한다
Continous binary vector
시퀀스의 각위치를 표현하는 d_model 차원의 encoding벡터를 만들었을떄, 그것이 연속적인 함수로 표현되면 좋을 것이다, 이를 sin함수를 통해 구현가능한데 sin함수는 [-1,1]로 값이 위치해있어 이미 정규화 또한 되어있다.

아래의 아날로그 음량 버튼이라 생각해보자 각 버튼인 [0 ,1]의 범위를 가지고 0과 1을 반복할 것이다.또한 512개의 음량 버튼이 존재한다고 했을 때 하나의 큰 버튼이 아니라 d_model개의 작은 버튼으로 부터 음량 레벨을 맞춘다 각 버튼이 가르키는 값에 따라 연속적인 특정 음량을 나타낼 수 있을 것이다 즉 맞추고자 하는 특정음량을 시퀀스의 위치라고 생각하면 해당 위치에 존재하는 d_model개의 dial의 0 /1을 조정함으로써 표현 가능하다는 것이다
Positional Encoding

Positional Encoding은 다음과 같이 주기 함수를 활용한 공식을 사용하게 된다 이때 sin함수나 cos함수말고도 다른 주기함수를 활용해도 괜찮다. 즉 주기함수를 통해 모델이 어떤 문장에 있는 단어의 상대적인 위치를 학습할 수 있게 된다면 그 형태는 상관없다.

학습을 통해 구한 일반 일반 임베딩 값과 위치 인코딩값을 element wise하게 더해준다. 그렇다면 위치정보를 가지고 있는 임베딩 값을 만들어 낼 수 있다!

