[CS231N] lecture13 review
in Summary on Summary, Cs231n
supervised learning
what is self supervised learning

13강에서는 이전장에서 배운 생성모델과 비교하여 self supervised 기법을 소개하고 있다 self supervised learning과 generator모델의 공통점은 두 모델다 레이블을 필요로 하지 않으면서 학습할 수 있다는 점이다 반면에 generator가 data를 생성하는 목적에 의해 학습하는 반면 self-supervised learning은 좋은 특징을 추출하는 인코더를 학습하는 것이 목표라는 점에서 차이가 있다.
이러한 인코더를 학습하기 위해서 다양한 방법들이 실험되었고 몇몇의 pretext task를 통해 특징을 추출하는 좋은 인코더를 학습시킬 수 있다는 것을 발견했다 이렇게 학습된 인코더는 훌룡하게 pretext task를 수행하는데 여기서 evaluate 되는 것은 task자체가 아닌 인코더를 통해 우리가 진짜 원하는 작업(downstream) ex)분류 을 수행함으로써 evaluate한다
predict rotations

4개의 모델이 이미지가 얼마나 기울어져 있는지 예측하는 작업을 수행한다 이떄 이미지의 특징을 추출하는 ConvNet은 weight를 공유하면서 학습한다. 이때 변화를 주는 각도는 통상적인 4개의 각도를 주는 것이 제일 성능이 잘 나온다고 주장한다. 아까 말했듯이 이렇게 학습된 모델에서 ConvNet만 가져와 downstream작업에 사용된다.
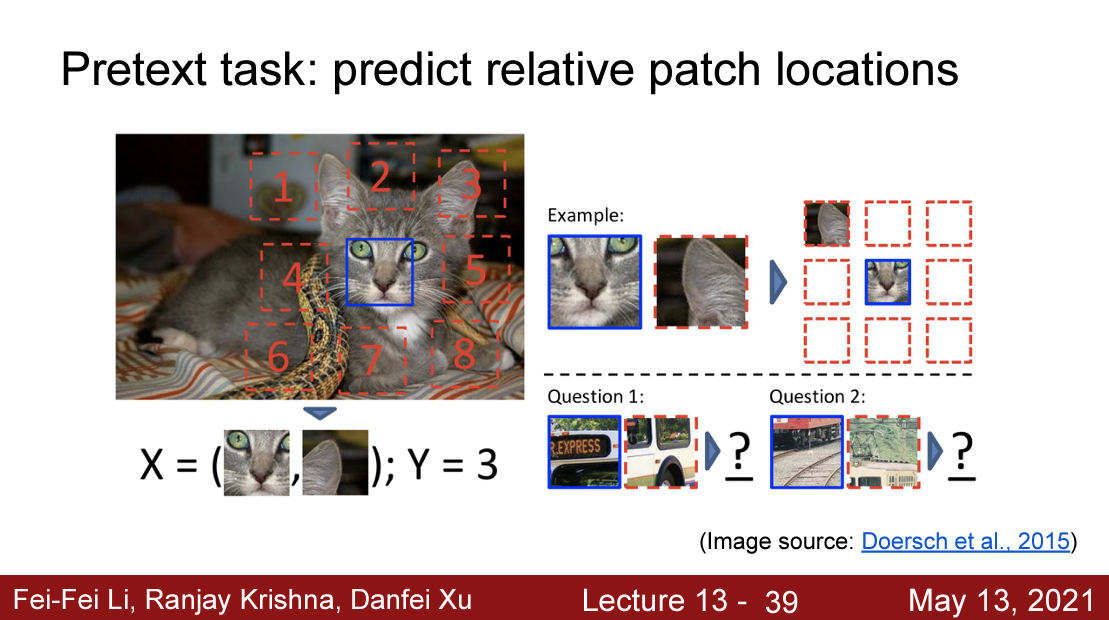
predict relative path location
다음은 predict relative patch locations 문제인데 가운데의 이미지를 기준으로 나머지 1~8에 위치하는 이미지를 맞추는 것이 목적이다 모델구조는 input으로 가운데의 이미지와 위치를 예측해야하는 이미지가 쌍으로 들어가기 떄문에 모델 2개가 형성된다. 이렇게 형성된 모델은 CNN을 통해 특징을 추출하고 올바르게 원래 위치를 예측한다 물론 CNN중 몇개의 층은 공유되면서 학습해 이후 downstream에서 사용된다.
###jigwar puzzle 
jigsaw puzzle문제도 마찬가지로 가중치를 공유하면서 여러개의 모델들이 작업을 수행할 수 있게 학습한다.

image crop
다음은 crop된 이미지를 input으로 받고 crop된 이미지를 복구하는 작업이다. encoder를 통해 이미지의 특징을 추출하고 이를 기반으로 예측한 이미지를 decoder로 생성한다 마지막으로 생성한 이미지와 원래 crop된 이미지를 label삼아 서로 비교하여 손실값을 최소화 한다

이것에 대한 loss식은 다음과 같다 여기에 adversarial loss를 추가하면 더 좋은 성능의 이미지를 샐성할 수있다.
image coloring

image coloring 은 객체의 앳지나 특징을 파악하는 네트워크와 색을 칠하는 모델 이 두개가 필요허다 F에서 특징을 추출하고 ab넷에서 색을 칠한다.
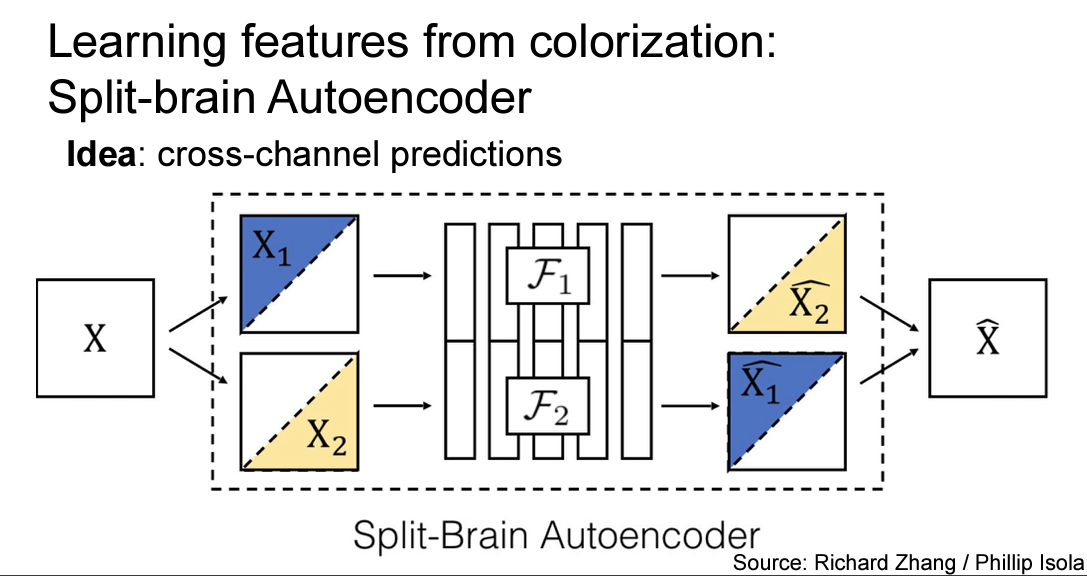
이후 coloring을 더 발전시킨 형태인 split brain autoencoder는 두개의 다른 체널색상을 교차로 예측하게 만들어 놓은 모델이다 이전의 단순한 색칠작업보다 성능이 더 좋았다. 
그 예시는 이렇다 input umage x를 그레이 체널과 다른 하나의 체널로 분리한 후 각각의 색을 에측하고 이를 합한다.
video coloring

이미지의 특징을 분석하여 객체가 어디에 있는지 상대적인 위치정보를 얻고 target이미지에서 추출한 색을 그대로 입혀준다.

식을보면 f가 여러가지의 객체를 의미한다고 하였을때 각 객체의 softmax를 통해 score를 얻게 되고 이를 통해 현재 색칠해야하는 객체가 무엇인지 알 수있다. 이를 c를 통해 색을 칠하게 된다. 그리고이를 ground truth와 비교하여 손실값을 최소화한다.
summary pretext task

이러한 작업들은 기본적으로 시각적으로 이상이 없어보이도록 학습을 하는데 목적을 둔다. 이렇게 아무의미 없어보이는 작업을 수행함으로써 우리는 좋은 특징을 뽑아내는 네트워크를 만들 수 있을 것이고 이는 downstream task에서 파인튜닝을 통해 훌룡하게 적용될 것이다. 하지만 이러한 작업들은 일반적이지 않다는 단점을 가지고 있다 예를 들어 분류작업을 수행하는데 있어 preidcit rotation이 좋은 pretext task일까 아나면 coloring이 좋을까 이런 과정을 매번 거쳐야한다 따라서 더욱 일반적이고 획기 적인 방안을 소개한다.
contrasive learing
contrasive loss를 통해 모델구조를 만든 학습 기법이라고 할 수 있다 이는 positive pair와 negative의 encoder를 학습시키는 방법그리고 negarive pair의 이용방법등에 따라 다양한 모델이 있는데 예를 들어 SimCLR , MOCO , CPC등이 있다 앞으로 살펴볼 모델은 컴퓨터 비전에서 활용되고 인코더 두개를 학습시키는 end-to-end방식의 모델인 SimCLR 이다

우선 Contraisive learing 이란 positive pair의 유사도는 최대로 하고 negative pair의 유사도는 최소한으로 하는 것이 목적으로 한다 그렇다면 positive pair란 무엇일까 이는 비슷한 이미지에서 추출한 특징벡터를 score화 한값들의 쌍이라고 할 수 있다. 따라서 negative pair은 서로다른 이미지에서 추출한 이미지 특징에서 score화 한 값의 쌍이라고 할 수 있다.
다시말해 서로 비슷한 이미지들에서 추출한 특징들은 서로 비슷해야 할 것이고 서로 다른 이미지에서 추출한 특징들끼리는 서로 다르게 만드는 것이 목적이다.
따라서 위의 loss식은 분모에 negative pair의 유사도 합산 + positive pair의 유사도 를 가지고 분자로 positive pair의 유사도를 가지게 된다 식에 -log가 적용되었으므로 분자는 커야하고 분모는 작아저야 loss가 줄어들면서 학습을 하게된다. 이 식은 softmax와 유사한 형태를 띄는데 이는 많은 pair쌍에서 positive pair의 score를 최대로하는 분류문제와 그 본질이 비슷하다고 생각된다.
마지막으로 아래의 부등식은 MI라는 상호정보량을 표현하는데 이것에 대한 정의는 두 데이터분포간 엔트로피 유사도라고 할 수 있으므로 우리는 위의 loss식을 통해 나온 부등식이 log(n)->negative pair의 수 이 많으면 많을 수록 그 성능이 더욱 올라가는 것을 볼 수 있다.
이렇게 contraisve learing을 통해 학습한 모델은 이미지의 특징을 추출하는 인코더를 가지고 있다. 이후는 pretext task와 마찬가지로 인코더를 파인튜닝을 통해 우리가 원하는 downstream task에 이용하면 된다.

위 구조는 contrasitive의 end-to-end방식중 하나인 SimCLR모델이다. 위 구조는 다음과 같은 방식으로 진행되는데
- mini batch의 N개의 데이터중 하나를 뽑아(x) 서로다른 agumentation을 적용시켜 x_i , x_j쌍을 생성한다.
- 이 두 pair를 깊은 CNN구조에 input하여 이미지의 특징 벡터 h_i ,h_j를 얻게 된다.
- 이렇게 얻은 두 특징벡터쌍을 MLP인 g model을 통해 비선형 투영을 시켜 contraisitive loss가 적용될 수 있는 공간으로 mapping 한다.
- 이렇게 구한 벡터쌍 z_i , z_j의 유사도를 만약 positive pair에서는 그 유사도를 최대로하고 negative pair에서는 최소한으로 만들어 준다

위는 positive pair를 만들때 적용되는 agumentation과정들이다

이때 표를 보게되면 color distrion 과 crop을 agumentation으로 하게되면 성능이 두드러짐을 알 수 있다.

위 그림과 아래그림은 SimCLR의 진행과정을 예시를 들어 보여주는 것이다.


코사인 유사도는 z벡터쌍의 유사도를 구할떄 사용하는 수식이다 두 벡터간의 방향을 수치화 해준다는 의미를 가진다



위와 같은 loss식을 변형하여 유사도 행렬을 만들어 한번에 학습을 하게 된다. positive vector를 concat한 것이 아닌 사이사이에 섞여 들어가게 만들어 색칠된 부분에만 positive pair가 들어가게 되고 나머지 index에는 negative pair가 들어가게되어 이를 활용한다.

물론 supervised learning에 비해서는 좋지못한 성능을 보이지만 상대적으로 레이블이 없는 환경에서 이 정도의 성능을 보이는 것은 대단한 아이디어인 것 같다.
2021-09-08일 추가수정
MOCO에 대해서
Moco, Momentum contrast for unsupervised visual representation learing이다 대충 해석해보면 시각적표현에 대한 순간 대조 학습법인 것 같은데….. 공부를 통해 이해할 수 있을 것 같다.
Moco이전의 contrasitive learning 은 end-to-end방식 , memory방식이 존재 하였다. 이중에서 end-to-end방식은 이전에 본 simclr구조를 말한다.

Contrasitive loss를 최대한 활용하려면 많은 수의 negative항이 필요하다 -> 이전에 살펴본 하한항 배치사이즈가 늘면 늘수록 모델의 성능은 올라간다. 이때 negative sample의 encoder는 query encoder와 consistent해야한다 왜냐하면 비슷한 데이터에서 좋은 특징(유사한특징)을 뽑아내기 위해서는 비슷한 인코더가 필요한 것은 당연하다.
end-to-end 방식은 mini-batch내에 존재하는 ample들을 negative sampel로 활용하는데 많은 negative sample을 사용하려면 computational limit이 발생한다 memory bank 방식은 많은 양의 negative sample을 활용할 수 있지만(와냐하면 negative항에서는 enocoder를 업데이트 하지 않으므로 ) encoder가 update됨에 따라 encoded된 negative sample은 갱신이 되지 않는다.-> 학습을 하지 않는다 -> 계속 같은 특징만 추출하게 된다.
이러한 end-to-end와 memory bank 방식의 단점을 개선한 것이 MOCO이다.
Method

Moco의 핵심아이디어는 1. negative representation을 저장하는 queue. 2. key encoder의 momentum update이다
MoCo는 simclr과 마찬가지로 하나의 이미지에 두개의 augumentation을 적용한다, 만들어진 유사한 이미지들은 similar로 정의한다 queue내에 존재하는 representation은 disimiar로 사용한다. queue내는 과거 batch내 augumentation이 image가 encode된 representation들로 이루어져 있다. 정의된 simliar와 disimliar를 사용하여 contrastive loss를 계산한다 encoder를 갱신하고 key encoder는 momentum update해준다.
현재 batch에서 augumenation된 이미지는 queue에 enqueue한다 queue내에 존재하는 과거의 representation은 deque한다. encoder가 갱신됨에 따라 과거의 representation은 consistent하지 않기 떄문이다 query encoder는 학습이 진행되면서 갱신이 되고, key enocder는 momentum 기법을 사용하여 서서히 갱신한다.
contrasitive learning as dictionary look-up

momentum update

code

코드를 보면 x_q 와 x_k는 서로다른 agumentation한 결과이다 그리고 만들어진 데이터쌍을 인코더를 통해 특징을 추출한 값이 크기가 NxC인 특징 벡터이다. 이를 벡터곱을 통해 유사도를 측정한다 따라서 bmm , mm함수를 통해 이를 수행하고 이를 concat한 것을 crossentropy를 통해 손실값을 구하고 backwarkd과정을 거친다
query enocder를 업데이트 해주고 key encoder는 momentum update해준다 마지막으로 학습을한 key value들로 queue를 change해준다
Experiment
